
【はじめに】
こんにちは。23年卒SD部M.Sです。
前回投稿されました「機械学習part3:決定木について」はお読み頂けたでしょうか?
まだお読みでない方は、ぜひpart3から続けてお読みいただけると本投稿の内容がより分かりやすくなるかと思います!
また、機械学習の概要について説明している「機械学習part1:機械学習とは」や、機械学習を実践するための準備方法を説明している「機械学習part2:機械学習実践に向けて環境構築をしてみよう!」も公開されています。お時間のある時にぜひお読み下さい!
前回のブログでは、実践を交えつつ「決定木」についてご説明しました。今回は決定木の応用編である「ランダムフォレスト」について、実践を交えつつ掘り下げていきます!
【目次】
・ランダムフォレストの概要
・ランダムフォレストの実装
①決定木モデルの作成
②欠損値の穴埋め
③文字データの列をダミー変数化
④特徴量と目的変数の定義
⑤ランダムフォレストを実装
・さいごに
【ランダムフォレストの概要】
前回のブログで解説をしている決定木は、以下の図1-1のようなものを示します。
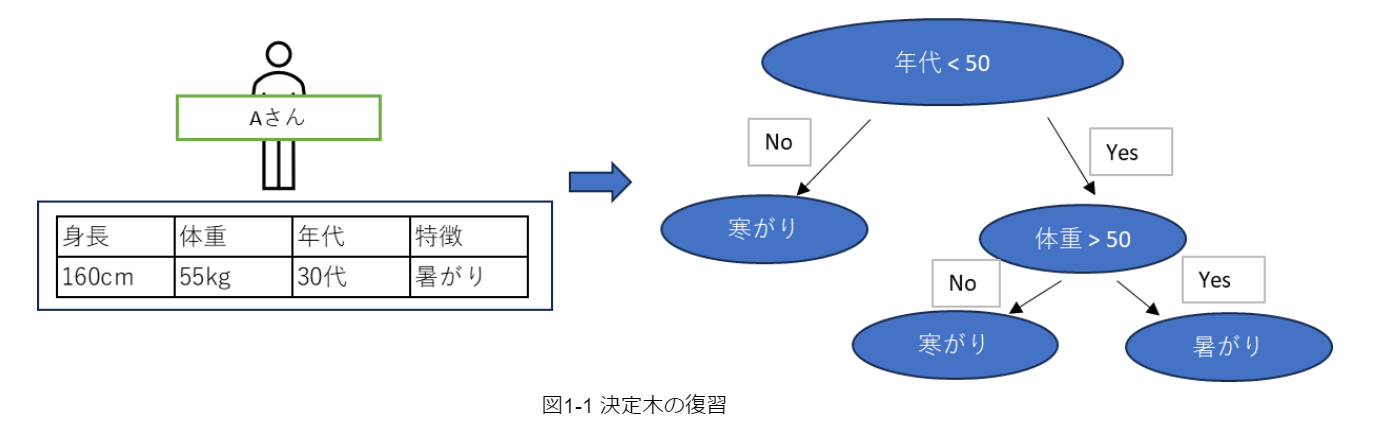
こちらの図では、例として「今日の服装は?」というテーマで決定木モデルを作成しました。この左右2つに分岐していくフローチャートのことを「木」と呼びます。
ランダムフォレストとは、たくさんの決定木を作成しそれぞれの木に予測させ、その結果の多数決で最終結果を求めるという手法です。(図1-2)

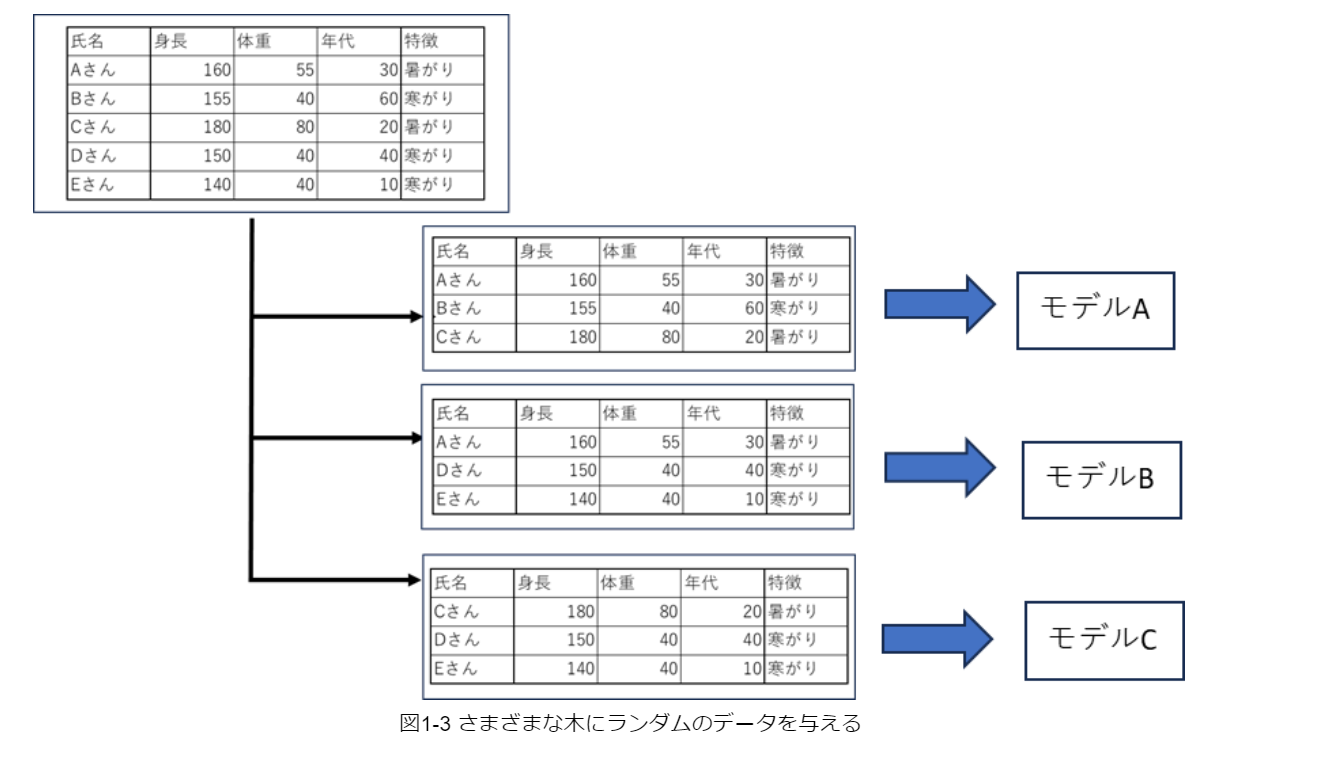
ランダムフォレストのように、さまざまな予測モデルを作成して、最終的に1つの予測結果を出す手法のことを”アンサンブル学習”と呼びます。しかし、「同じデータ」で「同じ決定木」分類をしたらそれぞれの木がすべて同じになってしまうので、アンサンブル学習の意味がなくなってしまいます。
そこで、各決定木で利用するデータは行も列もランダムに選ぶようにし、作成する木に多様性を持たせて、さまざまな木での多数決を行います。(図1-3)
【ランダムフォレストの実装】
それでは、早速ランダムフォレストの実装に移っていきましょう。実装するにあたり、須藤秋良著・『スッキリわかる機械学習入門』を参考にしています。
①決定木モデルの作成
まず始めに決定木モデルを作成していきます。前回の「機械学習part3:決定木について」とやり方は同じになるので、説明は簡略化させていただきます。
#モジュールの読み込み
import numpy as np
import pandas as pd
from sklearn.modal_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
%matplotlib inlineそして今回は、身長・体重・年代を特徴量とし、暑がり派か寒がり派かを正解データとする独自に作成したデータを基に、モデルを学習させていきます。
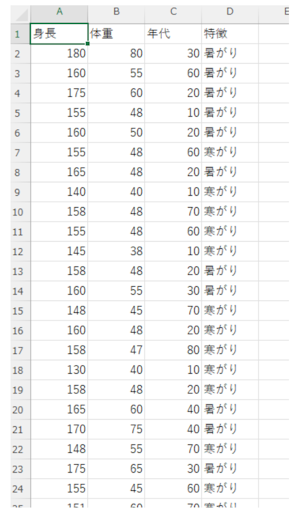
それでは、実際にこちらのCSVファイルを読み込んでいきます。
CSVファイルはあらかじめ適切なフォルダに配置しておきましょう。今回はdatafilesというフォルダに配置し、CSVファイルのファイル名はsample.csvとしています。
CSVファイルが読み込めないときは、【encoding='shift-jis'】を用いて文字コードを指定してあげましょう。
#CSVファイルの読み込み
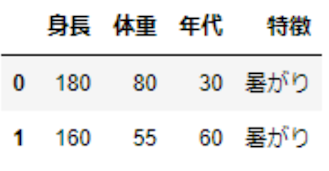
df = pd.read_csv('c://work//Blog//sukkiri-ml-codes//datafiles//sample.csv' , encoding='shift-jis')上記のコードを実行すると、以下のような結果が返ってきます。
②欠損値の穴埋め
続いて、欠損値の穴埋めをします。
欠損値とは、あるデータ内の変数において存在しない値のことを言います。例えば、アンケートを通してデータを集めるとします。アンケートを回答したすべての人が、完全な回答をしてくれるとは限りません。未記入の項目やデータが欠損してしまうことも考えられるので、欠損した値を対処しなければなりません。そこで行うのが、『欠損値の穴埋め』です。今回は以下のコードのような値で穴埋めを行います。
※決定木では外れ値の影響はほぼないため、外れ値に関する処理は行いません。
※データの標準化も決定木ではほとんど影響がありません。
#欠損値の穴埋め
jo1 = df['身長'] == 1
jo2 = df['体重'] == 0
jo3 = df['年代'].isnull()
df.loc[(jo1)&(jo2)&(jo3), '年代'] == 40
jo2 = df['体重'] == 1
df.loc[(jo1)&(jo2)&(jo3), '年代'] == 30
jo1 = df['身長'] == 2
jo2 = df['体重'] == 0
jo3 = df['年代'].isnull()
df.loc[(jo1)&(jo2)&(jo3), '年代'] == 20
jo2 = df['体重'] == 1
df.loc[(jo1)&(jo2)&(jo3), '年代'] == 10
jo1 = df['身長'] == 3
jo2 = df['体重'] == 0
jo3 = df['年代'].isnull()
df.loc[(jo1)&(jo2)&(jo3), '年代'] == 40
jo2 = df['体重'] == 1
df.loc[(jo1)&(jo2)&(jo3), '年代'] == 30
#目的変数’特徴’を数値に変換
from sklearn.preprocessing import LabelEncoder
label_encoder = LabelEncoder()
df['特徴'] = label_encoder.fit_transform(df['特徴'])
#欠損値の確認
print("欠損値の数:¥" , df.isnull().sum())
今回のデータでは欠損値はありませんでしたが、欠損値が存在していた場合には平均値を使って穴埋めを行います。
#欠損値を平均値で補完
df_filled = df.fillna(df.mean())
#補完後のデータで再度欠損値の確認
print("欠損値の数(補完後):¥n",df_filled.isnull().sum())③文字データの列をダミー変数化
続いて、文字データの列をダミー変数化し数値に変換していきます。
特徴列には文字データが入っていますが、データ分析を行う上で文字データを扱うことはできないため、「0と1」のようにして数値化をする必要があります。
#特徴量の列を参照してxに代入
xcol = ['身長', '体重', '年代']
x = df[xcol]
#正解データを参照しyに代入
y = df['特徴']
#特徴列は文字列なのでダミー変数化
dummy = pd.get_dummies(df['特徴'], drop_first = True)
x = pd.concat([x, dummy], axis = 1)
x.head(2)実行すると以下のような結果が返ってきます。
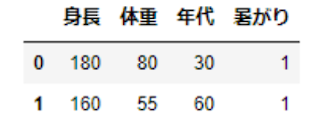
④特徴量と目的変数の定義
続いて、特徴量と目的変数の定義を行います。
決定木モデルがデータを理解し学習を行い、必要な情報を与えることで未知のデータに対して予測を行うために定義付けを行います。
#特徴量と目的変数の定義
col = ['身長', '体重', '年代']
x = df.drop(col, axis=1) #特徴量
y = df['体重'] #目的変数⑤ランダムフォレストの実装
ここまで長くなってしまいましたが、実際にランダムフォレストを実装していきましょう。
ランダムフォレストをインポートし、作成する決定木の数を指定します。今回作成する決定木の数は”100”と指定しているので、100個木が作られることになります。
『n_estimators』で作成する木の数を指定しており、木の深さの最大値はすべての木で共通です。
#ランダムフォレストのインポート
from sklearn.ensemble import RandomForestClassifier
x_train, x_test, y_train, y_test=train_test_split(x, y, test_size = 0.1, random_state = 0)
model = RandomForestClassifier(n_estimators = 100, random_state = 0)最後に、モデルの学習を行えばランダムフォレストは終了となります。
#モデルの学習
model.fit(x_train, y_train)
print(model.score(x_train, y_train))
print(mdel.score(x_test, y_test))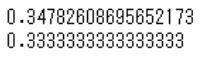
ランダムフォレストと決定木でのやり方を比べたいときは、以下のコードを参照し比較をしてみてください。
#決定木での予測
from sklearn import tree
model2 = tree.DecisionTreeClassifier(random_state = 0)
model2.fit(x_train, y_train)
print(model2.score(x_train, y_train))
print(model2.score(x_test, y_test))【さいごに】
全4回にわたり機械学習について紹介してきましたが、いかがだったでしょうか?
機械学習について事前知識はほとんどない状態でしたが、私たちの生活のいたるところで機械学習が用いられていたことに驚きました。また、実際にプログラムコードをかいてみると意外と簡単に実装を行うことができ、機械学習の概念を学ぶことができました。
今回はPythonを用いて機械学習を行いましたが、Python以外でも機械学習を行うことはできます。しかし、Pythonには用途に応じて様々なフレームワークが用意されているので、初学者の方でも学びやすいのではと思います。また、ランダムフォレストは機械学習part3で紹介した決定木よりも予測性能としては優れているので、データを分析する際には役立つかと思います。
今回紹介をしてきたもの以外にも、様々な機械学習の方法が存在しています。私たちはこれからも機械学習について学んでいこうと思っているので、ぜひ一緒に学んで行きましょう!
最後までご覧いただきありがとうございました。

